
Join us in building a fintech company that provides fast and easy access to credit for small and medium sized businesses — like a bank, but without the white collars. You’ll work on software wiring million of euros, every day, to our customers.
We’re looking for both junior and experienced software developers.
Data science is a hot topic in today’s tech scene, and many consider it one of the sexiest jobs on the market. But being a data scientist can be a puzzling experience. There is no clear-cut expectation on the expertise and responsibilities of such a professional.
When friends and family ask me what I do for a living, simply saying “I am a data scientist” won’t do the trick. After an initial wow-moment, it usually leaves them somewhat more confused than saying I’m a lawyer or a civil engineer.
Moreover, even amongst the tech savvy, the conversation usually does not end there either: it often unfolds with a “mmmm ok, but what do you actually do?”.
I believe the answer depends on the company you work for and here you can learn about my experience as a Data Scientist, or Machine Learning Engineer, at Floryn. And yes, naming is also a fuzzy aspect of the data ecosystem.
Simply put, at Floryn the data science team is responsible for building software that uses data. The goal can be to delegate to machines predictable and repetitive work, processing data to provide insights and calculations or measuring the quality of a system.
In theory, the software we officially develop and maintain comes in the form of prediction services. In other words, HTTP endpoints that can be queried (see Figure 1). They are written in Python, which is also our main expertise when it comes to programming languages.

In practice though, we interact with lots of different systems, wearing lots of different hats along the way of making Floryn a smarter company. Following a goal-oriented approach, we are responsible for managing everything that is necessary to achieve that.
Like many tech companies, what keeps Floryn running, is processes, software systems and people. I think the best way to describe how we fit into this picture is by picking a process as an example.
The process I want to pick is the Credit Risk Management process. This is the process that allows the company to do two things. Not losing money on customers that can’t afford to pay back their loan. Lending more money to the ones that can. It comes as the result of a complex analysis in which Risk Managers need to assess the situation of a company and make a decision.

In their quest to get to a decision, risk managers interact with different systems. The ones involved are Hubspot and the internal Floryn administrative platform, to which I will refer to as Admin.
Alright, so how does the process work? Hubspot is a CRM system that, amongst other things, runs ticketing pipelines. Tickets are created when a customer has to be assessed after he or she provides transactions data. When picking a ticket, risk managers will use Admin to find all the information they need, including raw bank transactions.
Floryn has thousands of active customers, and a way smaller pool of credit risk managers. So instead of hiring more to manage all the resulting workload, we build software that allows them to work in a smart way. Automate what is predictable, focus on what is necessary, act timely. This is our goal.
What does it take to prioritize the tickets that are created? How can we make sure that the tickets that are put first in the list are the ones that risk managers should focus on?
Recall the prediction services I mentioned earlier? Well if you zoom out and look at the rest of the ecosystem in which they operate you would end up with something that looks like the tech stack in Figure 2.
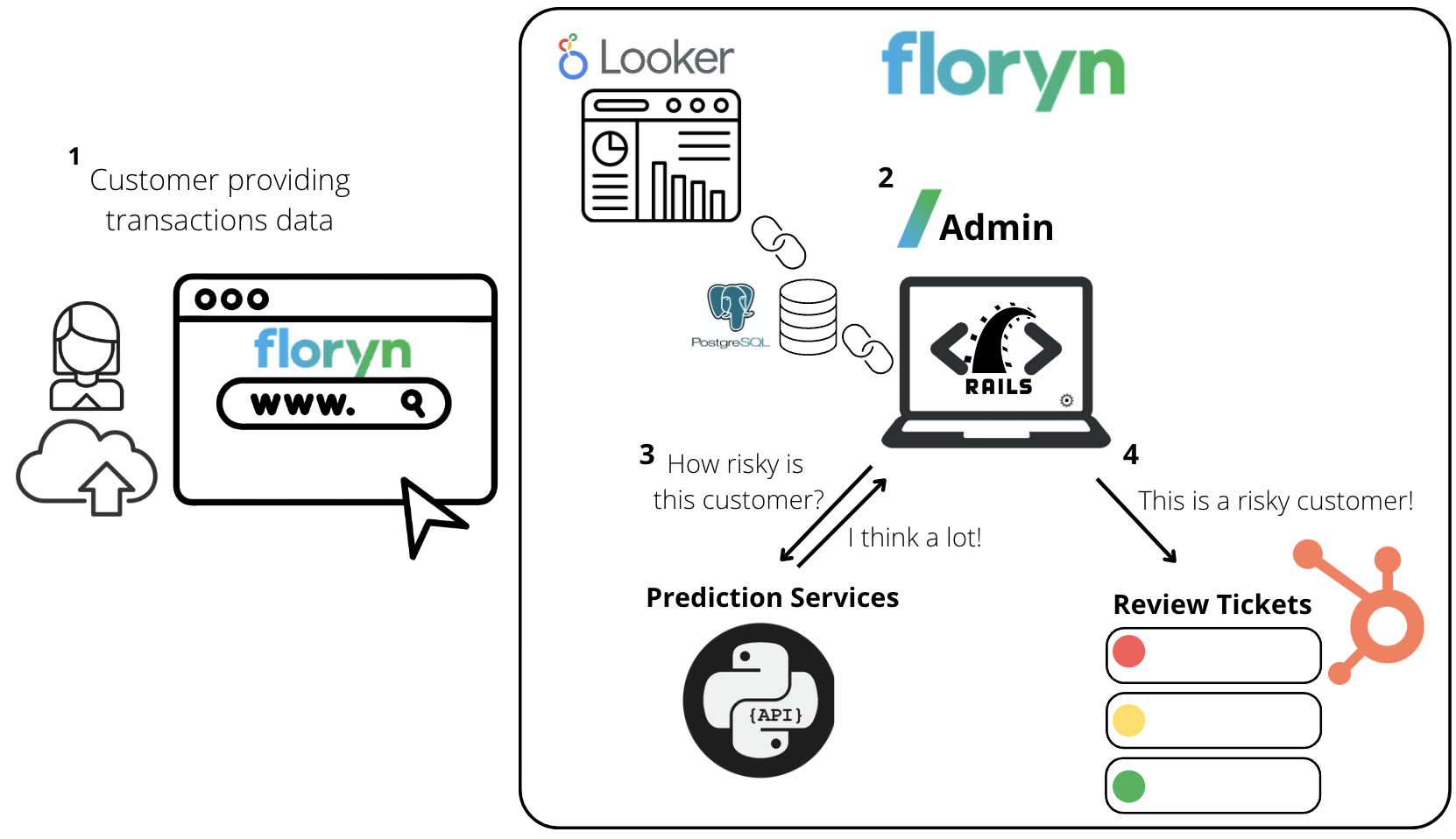
When a customer uploads their banking data, it is parsed and stored in the Admin, which technically speaking is a Ruby on Rails app backed by a PostgreSQL database. The Admin will then query the prediction services in search of a risk estimate. Once the response from the service is collected, it will be pushed to Hubspot. Hubspot uses this information to categorize customers into high, medium and low priority in the Credit Risk tickets pipeline.
One last bit worth mentioning is that in order to monitor how this whole machinery is performing we use Looker, a dashboard tool. It allows us to access information such as the number of tickets and the number of false positives.
You might be able to get the gist now. Making this happen entails working at the intersection of many of the systems running within the company. It also entails being able to collect information and user requirements from the business stakeholders involved, the credit risk managers.
I hope this blog post gave you some insight into what being a data scientist at Floryn looks like, and that the next time someone tells you he or she is a data scientist you will not be as confused about what that actually means ;)
Floryn is a fast growing Dutch fintech, we provide loans to companies with the best customer experience and service, completely online. We use our own bespoke credit models built on banking data, supported by AI & Machine Learning.
