
Join us in building a fintech company that provides fast and easy access to credit for small and medium sized businesses — like a bank, but without the white collars. You’ll work on software wiring million of euros, every day, to our customers.
We’re looking for both junior and experienced software developers.
Data-driven organisations rely on accurate and consistent information. How do you ensure integrity in a constant influx of new data and application change requests?
A robust validation strategy is imperative! One of the many tools and techniques that are available to us that has proven both nuanced and powerful is SQL triggers.
Let’s outline a simple model to illustrate it. The goal is to risk classify customers based on various data points using a decision tree. The model involves a classification having multiple checks that contribute to the overall result:
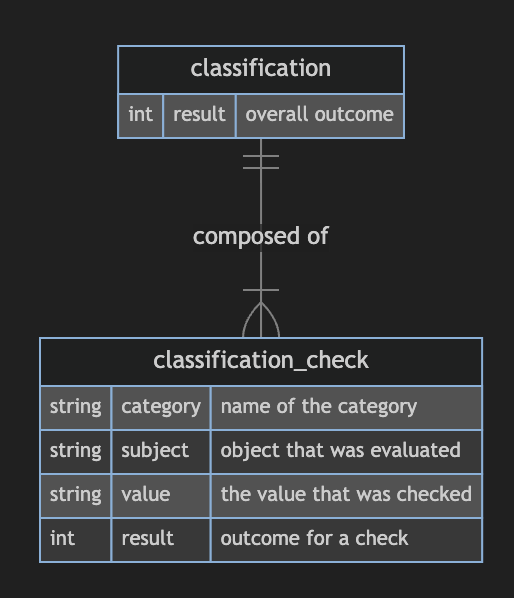
Consider a scenario where customers are classified in low and high risk, based on both their sector and country. We can represent the result with a number ordered by the risk, being 0 - low and 1 - high.
Depending on the info associated with the customer, they can fall into different result values for each check. The overall classification is then determined by the maximum value obtained from the checks.
But looking at this you might be wondering, “Why go through the trouble of denormalizing the result fields? Wouldn’t it be simpler to avoid denormalization altogether?” This is a valid question, and the answer lies in the benefits denormalization brings, particularly in terms of reporting simplicity.
Denormalization is simplifying the structure of our database by storing redundant data. In the context of our classification model, denormalizing the result fields allows for easier and more efficient reporting.
Suppose we want to generate a report showcasing the distribution of classifications by sector and country. With denormalized result fields, the data necessary for reporting is readily available in a single table, so it can be reported on without having to navigate complicated and potentially expensive joins.
Giving up a bit more storage is well-justified considering the efficiency and simplicity gained in reporting.
You might have already spotted but we need to ensure that the overall result of a classification aligns with its related checks at any given time.
Let’s jump into how SQL triggers can help in validating this consistency. If you’re unfamiliar with SQL triggers, the documentation at postgresql.org is always a valuable resource to visit.
It will look like:
create constraint trigger trigger_classification_result_consistency
after insert or update of result
on classifications
for each row execute function classification_result_consistency();
First thing to notice is that we are not creating just a normal trigger, but a constraint trigger, which is a special type of trigger that is closely tied to maintaining data integrity within the database. Unlike regular triggers that can respond to a variety of events, a constraint trigger is specifically designed to enforce integrity on the data, ensuring that it meets predefined conditions.
Sounds like our superhero here to ensure that the specified conditions are met after every insert or update operation on the result column of the classifications table! 🦸
In the above code, the trigger trigger_classification_result_consistency calls the function classification_result_consistency() which is responsible for testing the conditions we want to guard:
create function classification_result_consistency()
returns trigger
language plpgsql as $$
declare
consistent_result integer;
begin
consistent_result := (
select max(result)
from classification_checks
where user_id = new.user_id and classification_id = new.id
);
if new.result <> consistent_result then
raise exception 'Result in classifications should be "%" based
on classification_checks', consistent_result;
end if;
return new;
end;
$$;
We use plpgsql for the example, but feel free to use your procedural programming language of preference!
In this function, we can see how it is checked that the result in the classifications we are adding (identified with the new keyword) aligns with the aggregated results of the related checks (consistent_result, the maximum). If inconsistencies are detected, an exception is raised.
Following the same approach, we can write a trigger for the classification_checks table.
But wait, what if we are inserting the classification and its related resources all at once after the logic was run and came up with the result? That would be a problem for our trigger, because the data we are validating against will not be there yet.
We can use the deferrable initially deferred constraint, another powerful feature in PostgreSQL!
This ensures that triggers are deferred until the end of the transaction, preventing unnecessary trigger activations during intermediate steps of a bulk insert or update.
create constraint trigger trigger_classification_result_consistency
after insert or update of result
on classifications
deferrable initially deferred
for each row execute function classification_result_consistency();
With our triggers in place, we can now confidently say that our data is not only easy to report on, but also remains reliably consistent.
Let’s highlight some of the benefits that we brought into the table with this type of validation:
All in all, we’ve chosen a straightforward, efficient, and automated approach to guarantee real-time data consistency, without the need for introducing anything more complex than additional SQL statements!
So… are you incorporating these triggers into your database strategy and elevating the data consistency game?
Floryn is a fast growing Dutch fintech, we provide loans to companies with the best customer experience and service, completely online. We use our own bespoke credit models built on banking data, supported by AI & Machine Learning.
